
Content navigation:
- Introduction
- Machine learning in pricing models
- Price optimization and prediction models
- Machine learning in retail: dealing with data
- Machine learning is for everyone
- The future belongs to machine learning
On the popular game show The Price is Right, players must attempt to guess the price of products in order to win. What is not evident on the show, however, is that the retailers setting the prices of these products are often guessing as much as the players are. For both parties, their predictions don’t always lead to victory.
The contestants and retailers run into the same issue when trying to figure out the right prices: we can’t solve complex algorithms in our head fast enough to come up with a truly accurate number in time, so we have to make an educated guess and cross our fingers.
Machine learning doesn't have this issue, so it’s no surprise that retailers are increasingly adopting it to empower their teams. This article will explain how machine learning can help retail teams win the retail pricing game as well, and why every retailer should invest in ML-based pricing optimization to enhance their pricing teams and be a strong player in the modern market.
Get A-Z guide on price elasticity to adjust your pricing strategy to current trends and demands.

Machine Learning in Pricing Models
The main dilemma for retail teams when trying to accurately price their products is when they attempt to tackle this question: What is a fair price for this item considering the market, the current time of year, demand, and the product’s attributes? This question is insanely hard to answer correctly, because these factors are constantly changing.
Depending on the product, they can change in a matter of minutes, especially in the eCommerce market. This is why retailers like Amazon change the prices of their products millions of times per day. For retailers that are not as large as Amazon, however, doing so is painstakingly difficult. They are left with no choice but to compromise; either don’t consider many factors in order to change the prices in a timely manner, or consider as many factors as possible and hope that the market hasn’t changed too much by the time prices are set.
Traditional approaches to pricing rely on 100% human-powered decisions. The illustration below gives a glance at the fundamental difference between human-supervised ML-driven pricing and 100% human-powered one.

Machine learning can utilize complex algorithms in order to consider a myriad of factors and come up with the right prices for thousands of products near-instantly. ML-based pricing models can detect patterns within the data it is given, which allows it to price items based on factors that the retailer may not have even been aware of.
New information can always be added to further refine the estimates ML pricing models give as time goes by. Essentially, this means that not only are ML models more accurate than traditional pricing methods to begin with, but they also continue to become even more accurate as retail teams use them over time.
Price Optimization and Prediction Models
Machine learning can go a step beyond accurate pricing models for retailers as well. When it is applied to price optimization, ML-based algorithms can also be used to accurately predict how customers will react to certain prices and forecast demand for a given product. Price optimization using machine learning considers all of this information, and comes up with the right price suggestions for pricing thousands of products considering the retailer’s main goal (increasing sales, increasing margins, etc.) to make the pricing decisions of pricing managers more profitable.
Pricing optimization with machine learning also minimizes the risk usually involved in changing prices thanks to its prediction capabilities. Retail teams can essentially use machine learning to test out various promotions or pricing strategies to understand what its impact may be, turning their educated guesses into a data-backed science.
In other words, price optimization using machine learning doesn’t just give one potential price for a product — it can give pricing teams the best price considering a myriad of conditions, meaning it gives the best price for sales, best price for revenue increase, best price for promotion, etc.
As you've seen in the picture above, the capabilities of ML-enhanced pricing are incomparable with the human-only approach. Competera's predictive models are not only capable of processing 60 pricing and non-pricing factors at once, but also help pricing managers save 4 hours in each repricing cycle. In addition to that, our price optimization software enables retail teams to shift from SKU-based to portfolio-level pricing with no limits for the number of categories or products being managed.
Using machine learning algorithms to optimize the pricing process is a must for pricing teams of mature retailers with at least thousands of products to reprice regularly. As the technology is gaining popularity in the industry, the ability to manage ML-powered software will soon be an indispensable part of a pricing or category manager’s job description. There’s simply no way around it, as it gives pricing managers the unprecedented level of precision and speed of decision-making across any number of products.

The predictive capability of ML-enhanced pricing optimization gives retail teams a lot of room for experimentation with the knowledge of how customers will react to their strategy, so they can utilize whichever strategy they prefer, whether that be competitive pricing, dynamic pricing, keystone pricing, etc. No matter what they choose, they know what the outcome will likely be, and they know what the best price for that strategy is.
Machine Learning in Retail: Dealing with Data
The amount of data in retail is growing and becoming impossible to manage manually. Thus, businesses which seek to optimize their operational efficiency start using algorithms to make pricing recommendations and predict sales and allow managers to switch to strategic tasks.
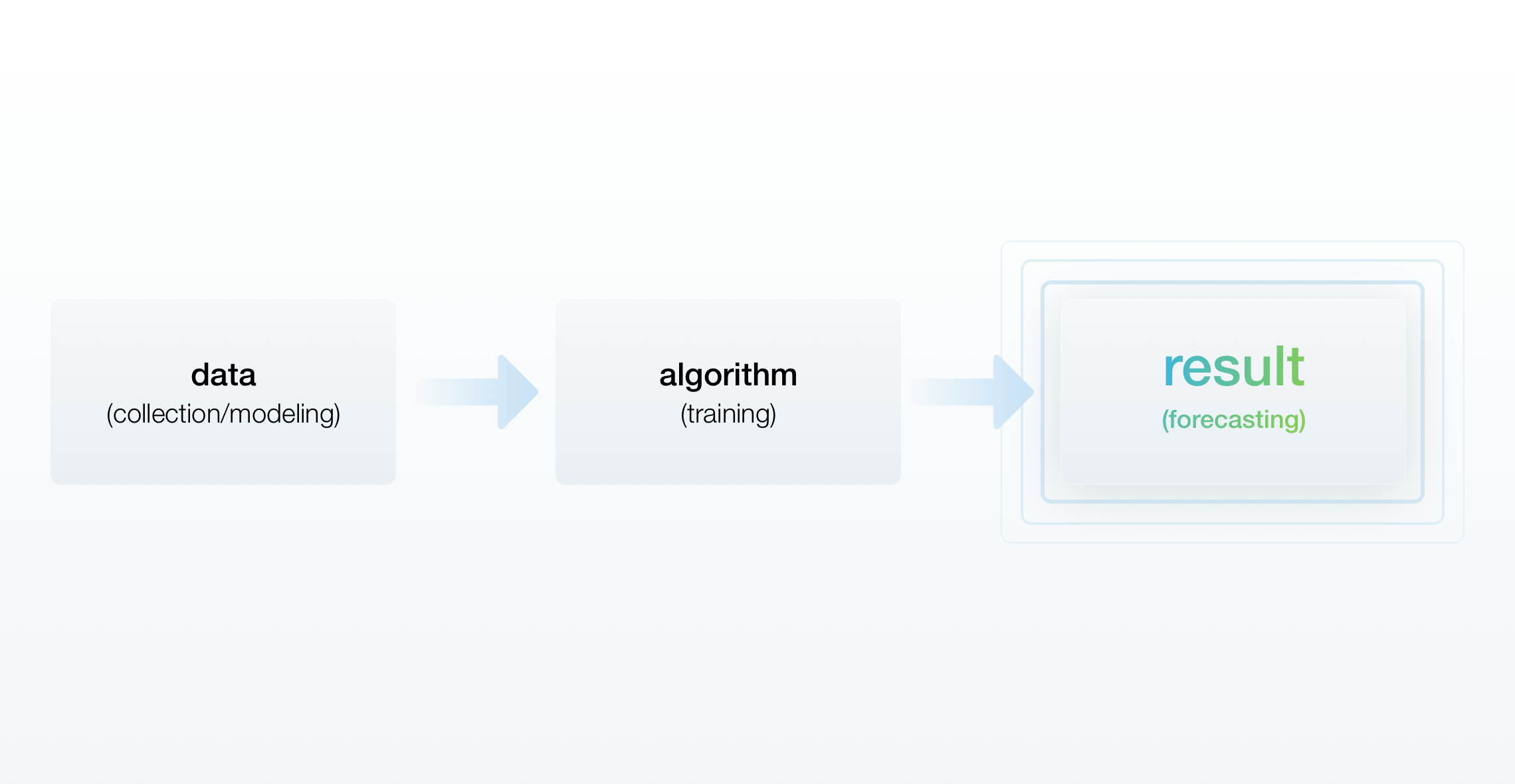
Before deploying, algorithms need to learn based on historical and competitive data. The model (or the algorithm) analyzes every single variable that impacts sales, such as pricing and traffic, during the learning stage. Once the training is over, and the algorithm makes accurate predictions which are later proven by real results, the model is ready for a pilot and, if the retailer is satisfied with the outcome, for further usage.
Very often, retailers have either incomplete, difficult to extract or ill-structured data in a wrong format. Below we'll cover the ways machine learning deals with insufficient data in retail.
Causes of Missing Data
-
The format is different from before. New internal systems, IT solutions, as well as the difference in data collection methods (whether it is by day or by transaction) can cause such a difference.
-
The data was initially collected for other purposes. For example, for top management to pay bonuses to the Category Managers — such data is not eligible for the algorithms.
-
The retailer has not been in the market long enough. As a result, the initial sales are nearly entirely reliant on the site traffic, making it difficult to analyze how prices impacted sales during that time frame.
-
The retailer has sales data for various departments or brands for short time periods — algorithms cannot work properly due to that mixed sales data.
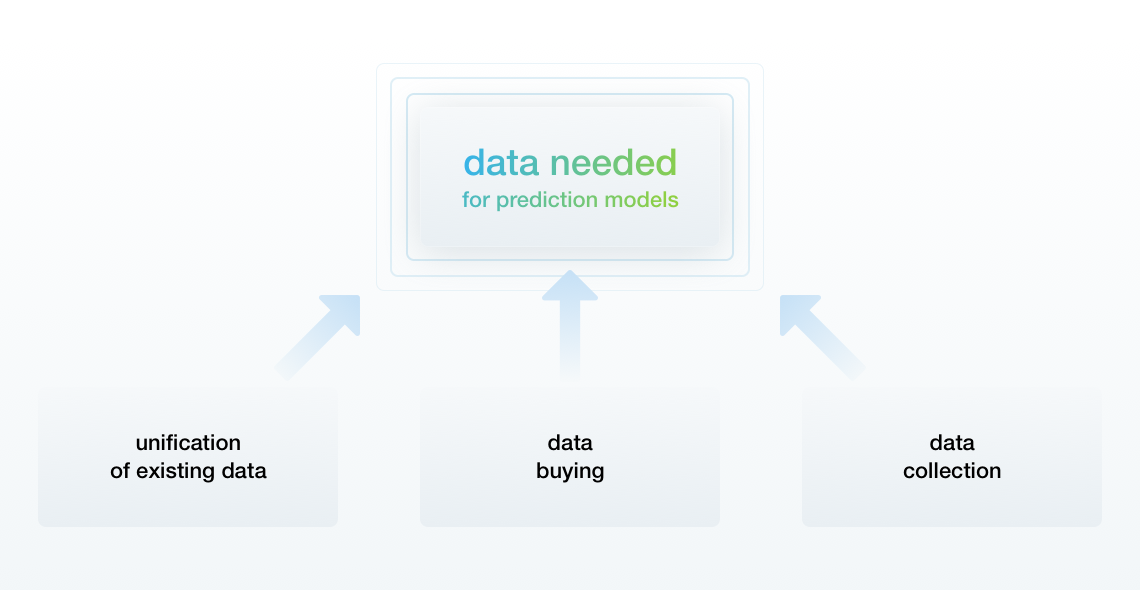
If the data is incomplete, retailers can either attempt to use everything they have or simulate the missing data.
Working with Existing Data
Retailers have to merge all of the data into one format. Also, if a retailer has already collected some data, but then new data is added based on other factors, for example, competitive prices, the business needs to wait for nearly a year to start collecting fresh data.
Another way is to purchase the missing data.
If there is no way to obtain the necessary data, the algorithms can use data modeling methods to simulate it.
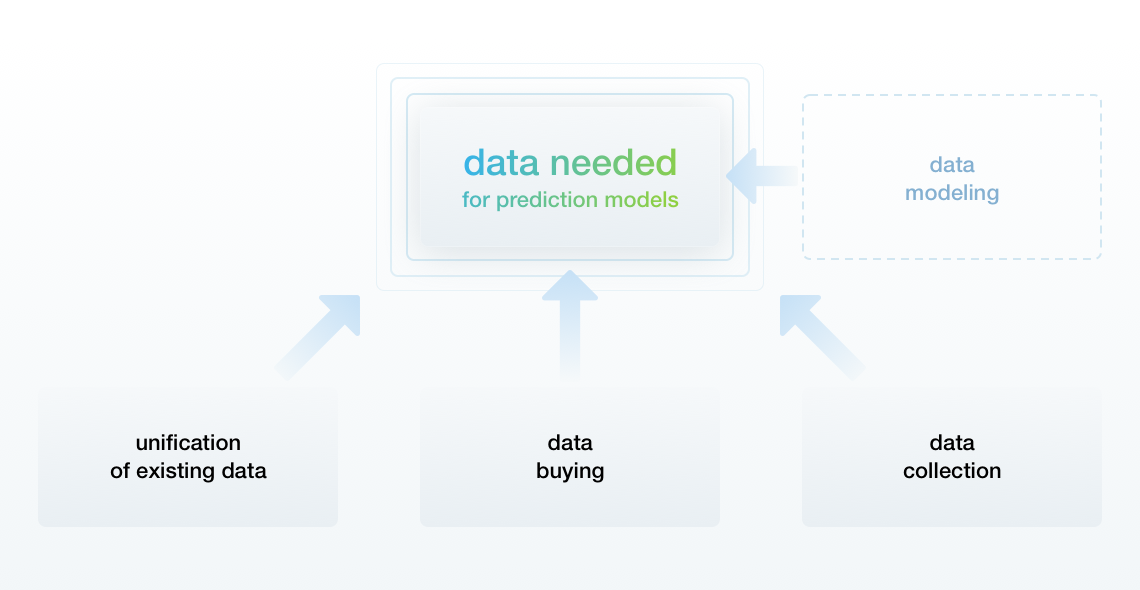
Although such models do not make entirely precise predictions and require more time for training and more data to be modeled, they are effective and retailers use them extensively.
Lost Data Simulation
The model can use the current data of a specific variable to define potential missing values of other variables. For example, if a retailer’s prices and sales history spans the past two years, while their competitor’s history of prices spans the past year and a half, a simulation can help restore the missing data about the competitive prices.

Businesses use classifiers to resolve such issues. They define potential values through various independent variables that have data.
There are two ways of “smart” data simulation with the help of classifiers:
The Predictive Model
The existing data is split into two groups:
- current data used as the train set
- missing data used as the forecast goals
A binary classifier helps to understand whether an event happened; for instance, whether the products had been on the shelf. A categorical classifier appoints a product to a specific segment, for example, a price segment.
The KNN (k-nearest neighbor) Method
This approach “restores” the missing values based on the “closest” variable. The approximate distance between them helps to understand how similar the variables are.
The churn predictor is the most known example of a classifier; it depicts the probability of customer churn for either a retailer or a service company. The five most commonly used classifier types include logistic regressions, decision trees, neural networks, boosters, as well as Random Forest.
As soon as the values that were missing are predicted, regressors, which are another type of algorithms, are used to predict sales. They do not predict a segment or the probability, but rather the numerical value, which in retail is sales.
Linear and polynomial regressions, neural networks, regression trees, and Random Forest are the most commonly used regressor types.
Machine Learning is for Everyone
With such an advanced technology, many retailers think that it is a hefty investment reserved for retail giants like Walmart or Amazon. Though it is true that these companies are definitely utilizing ML-based algorithms to price their products, this technology isn’t exclusive to them. Setting up an in-house ML-based pricing optimization platform is definitely a huge investment that for smaller retailers may not be worth its cost.
Luckily, external software providers are already incorporating machine learning within their pricing solutions, making the technology available to nearly every retailer willing to invest in new software. Purchasing the services of an external software provider costs a fraction of the amount it would take to set up an in-house system, and because this software is their main focus, the usability of the product is likely to be much better than anything created from scratch by a retailer.
Price optimization software has come a long way in the past decade, and thanks to AI and machine learning, it’s about as close to perfect pricing as a retailer can get. And despite its recent developments, ML-based pricing optimization is very established; study after study exists proving its ability to increase sales and revenue, even within relatively short timeframes.
The Future Belongs to Machine Learning
It is a general future trend that AI and machine learning will be incorporated into most software in one way or another, and the story is no different for pricing optimization. As pricing software providers continue to use ML-based algorithms and enhance its capabilities, more and more retailers will have access to the solution for their pricing dilemmas.
At Competera, we are looking towards the future where retail teams will no longer be guessing the right prices for their products, and where every offer we see from retailers will be based on indisputable data, complex pricing models, and accurate forecasting. We believe that the combination of ML-fueled demand-based pricing and rule-based dynamic approach empowers retail teams to find the most effective, balanced, and sustainable way to provide every customer with a unique shopping experience.
FAQ
The price of products powered by machine learning depends on the complexity of the algorithms and architecture of every solution. The more sophisticated a solution is, the more it costs. In contrast, a simple ML-powered product would be rather non-expensive.
The cost of machine learning is high as it takes a lot of human and time resources to design, train, and maintain a model able to solve complex tasks quicker and more effectively than humans may do.









